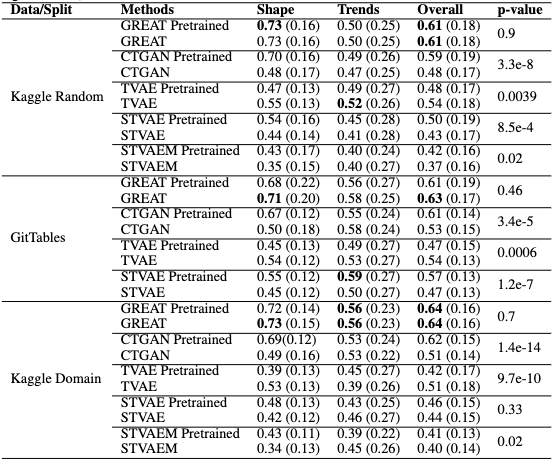
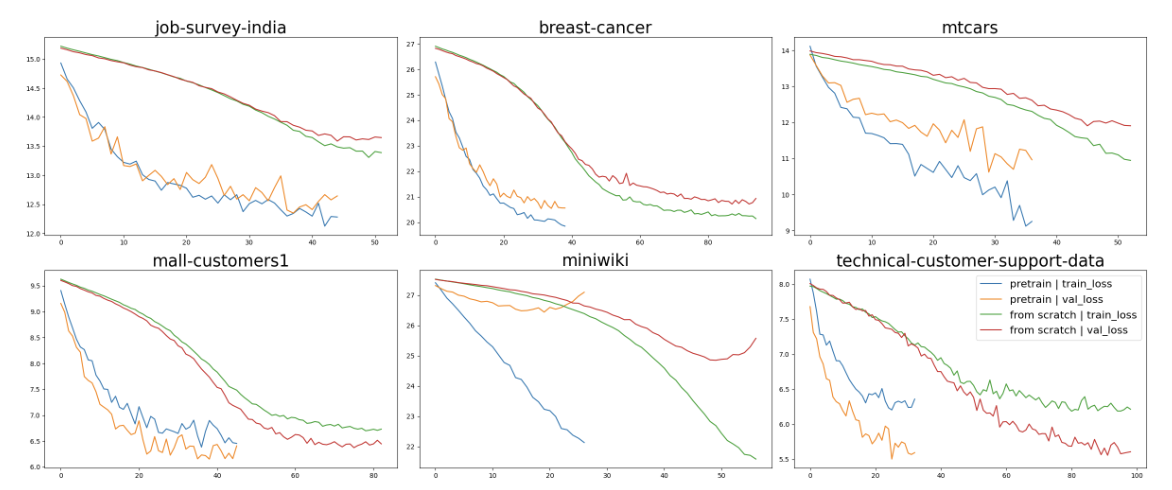
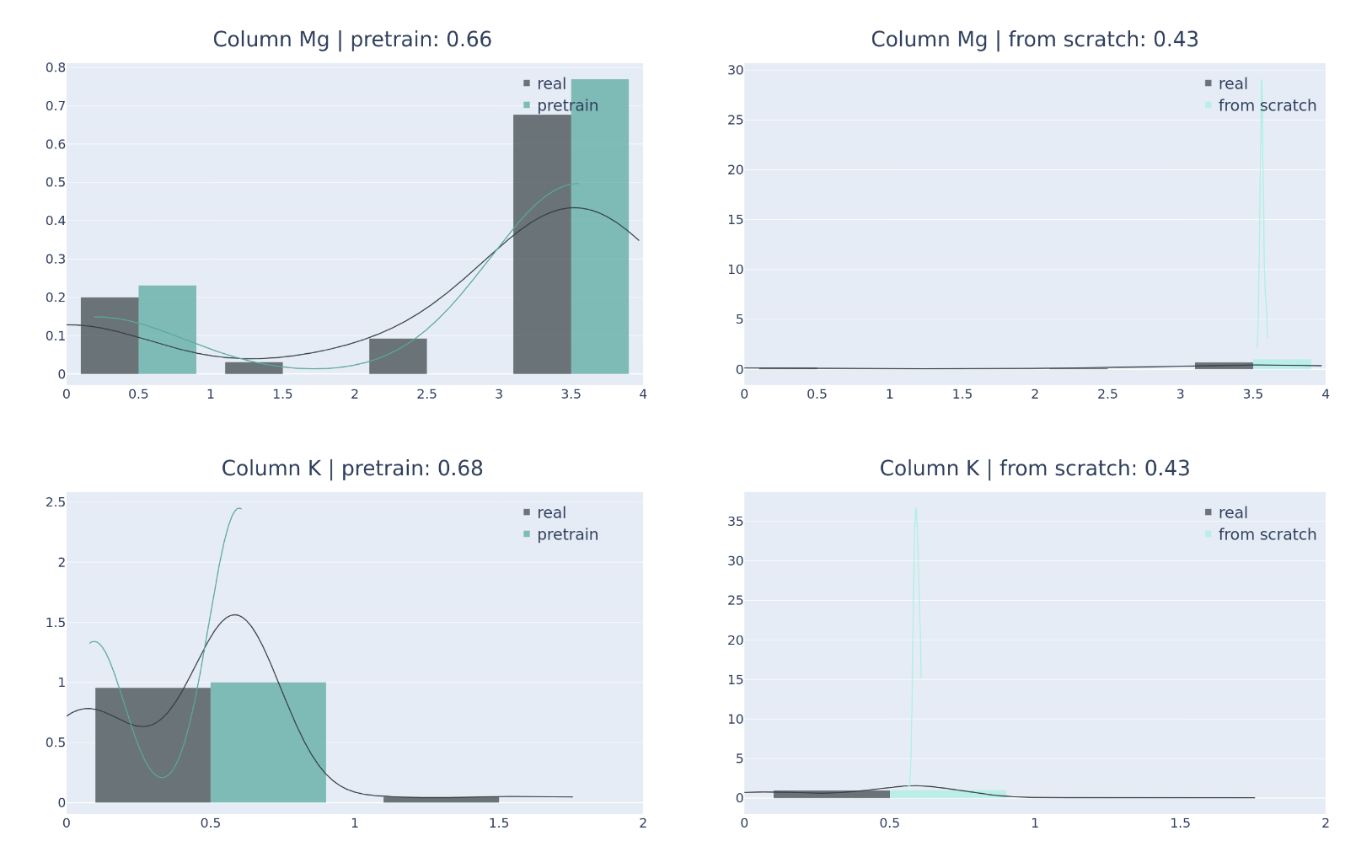
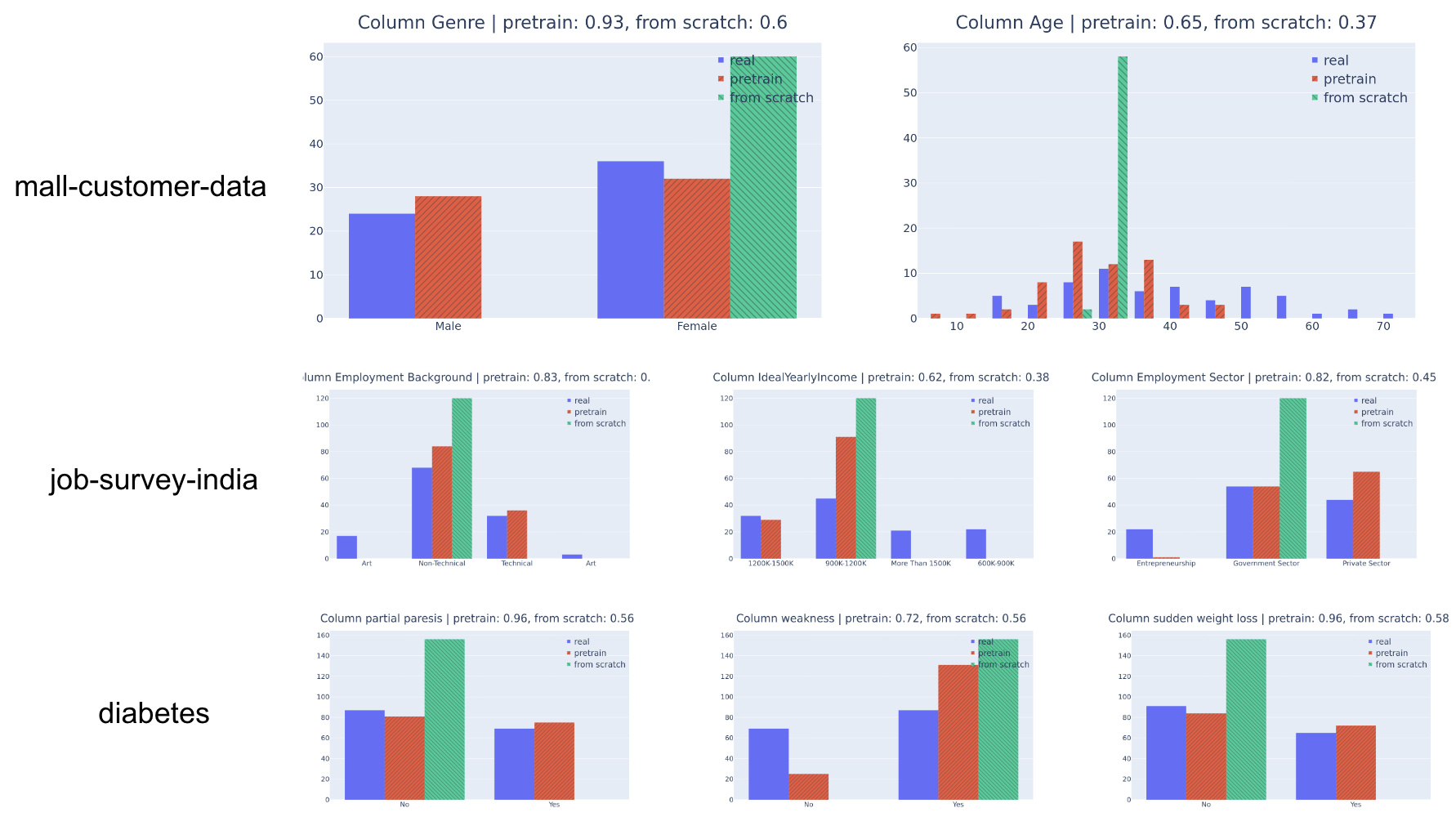
Foundational models (FMs), pretrained on extensive datasets
using self-supervised techniques, are capable of learning
generalized patterns from large amounts of data. This reduces
the need for extensive labeled datasets for each new task,
saving both time and resources by leveraging the broad knowledge
base established during pretraining. Most research on FMs has
primarily focused on unstructured data, such as text and images,
or semi-structured data, like time-series. However, there has
been limited attention to structured data, such as tabular data,
which, despite its prevalence, remains under-studied due to a
lack of clean datasets and insufficient research on the
transferability of FMs for various tabular data tasks. In
response to this gap, we introduce a framework called TabularFM,
which incorporates state-of-the-art methods for developing FMs
specifically for tabular data. This includes variations of
neural architectures such as GANs, VAEs, and Transformers. We
have curated millions of tabular datasets and released cleaned
versions to facilitate the development of tabular FMs. We
pretrained FMs on this curated data, benchmarked various
learning methods on these datasets, and released the pretrained
models along with leaderboards for future comparative studies.
Our fully open-sourced system provides a comprehensive analysis
of the transferability of tabular FMs. By releasing these
datasets, pretrained models, and leaderboards, we aim to enhance
the validity and usability of tabular FMs in the near future.